
最近刷屏的 GEN-1 有一个非常重要的 feature,就是它的执行速度非常“快”:能够以一种明显不拖沓的节奏完成任务,并相较此前方案实现了约 3 倍提速。而这一效果的取得,“依赖系统级组件”,并“不只是模型权重”的改进。
事实上,关于 GEN-1 极速执行的底层逻辑,Generalist 在最新技术报告中给出了答案:GEN-1 并非一个机械叠加机器人动作模块的微调版视觉语言模型(VLM),也不仅是一个世界模型,而是一个面向物理交互、具备“一等公民”地位的原生基础模型。
这与原力灵机坚持的技术路线高度一致。原力灵机明确提出“具身原生”这一全新 AI 范式,将其作为具身智能的核心实现路径,彻底区别于行业普遍采用的“嫁接式训练”,从智能本质与形成机制上扎根于物理交互。
正是基于这种深耕物理世界交互的共识,比较巧的是,恰好在最近一段时间里,我也专门研究了在 VLA 控制下如何让机器人真正快速地运动起来。相关结果最终整理为题为《Realtime-VLA V2》的技术报告,并已公开在:
文章:https://arxiv.org/abs/2603.26360
视频与rrd文件:https://dexmal.github.io/realtime-vla-v2
代码:https://github.com/dexmal/realtime-vla-v2
总结来说,我们实现了以数倍于遥操作采集训练数据的速度执行 VLA,并且在多个真实场景任务上完成了验证。

在三个不同任务上比较遥操演示速度(上)算法运行速度(中)和人手操作速度(下)
当然,要做到这一点,绝不是靠一个“巧妙算法打天下”,而是“端到端的全面踩坑”。下面我按照时间顺序,记录一下整个推进过程。
遥操作数据最初甚至无法录制
出乎意料的是,整个项目的第一道难关,竟然是遥操作数据本身难以采集。
由于我们的目标是在“真实”场景中研究任务执行,而不仅限于传统的“叠衣服”类 demo,因此我们还选择了一些来自工业客户的摆放类任务。例如在视频展示的上料任务中,需要将工件放置到工装上,这一过程要求 sub-mm 级精度,稍有偏差就会发生卡滞。我最初尝试亲自进行遥操作,结果发现这个任务几乎无法顺利完成,一度怀疑它是否具备可行性。
但反复尝试之后,我们逐步总结出一套有效的方法论。概括来说,核心在于:心要静。是的,这看似“玄学”的诀窍,背后对应了我们针对遥操作员的若干重要优化:
尽可能将动作设计成“机器人友好”的形式,减少必须依赖超高精度控制的步骤占比
允许主臂基座灵活调整位置(DOS-W1 支持该能力),为遥操作员提供更舒适的姿态,降低疲劳
每采集 1 小时,固定休息 10 分钟
在采集初期接受效率较低的现实,直到慢慢达到“人臂合一”的无我境界,采集效率自然上去
总体来看,目标是让遥操作员尽可能建立起对机器人末端的直接控制感,在视觉、触觉反馈和动作执行之间形成稳定耦合,从而提升采集质量与一致性。
我们不得不承认,人类本身依然是一个超强真实世界自主RL agent。经过一系列优化后,演示数据总算可以较稳定地录制出来。不过即便如此,采集到的演示速度仍显著低于最终应用需求。换句话说,从项目一开始,我们就必须把目标设定为:“推理速度要远超训练数据本身”。
充满细节的时序问题
有了数据之后,自然就是尽快 finetune 一版 VLA,再结合 RTC 算法缩短每一步之间的间隔,看看效果。
结果也并不意外:系统很快暴露出问题。我们发现,如果想以合理成功率完成任务,别说超过演示数据的速度(定义为 1x),实际上往往需要降到 0.75x 甚至 0.5x 才能稳定运行。
这是否意味着当前 VLA 模型能力不足?为此,我们做了更深入的排查,并发现一个非常关键的问题:推理与执行链路中的时序延迟远比预期严重。
为了验证这一点,团队做了一个简单实验:测量控制指令从发送到真正被机械臂执行,以及从执行到传感器反馈可观测之间的时间差。
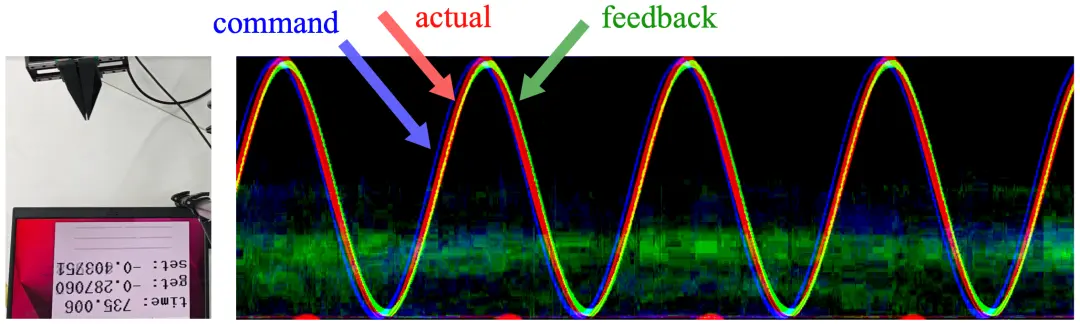
结果非常明确:给机械臂发送位置指令后,通常需要约 150ms,机械臂才能实际运动到对应位置;随后还要再经过约 50ms,我们才能从传感器反馈中观察到这一变化。这个时延显著超出我们此前的预期,也明显不同于以往在 UR 等工业机械臂平台上的经验。
这一现象其实不难理解。我们所使用的是桌面级轻量机械臂,其控制系统往往会对输入进行显式或隐式平滑,以避免运动过于抖动。但由于机械臂 API 并不提供对未来轨迹的原生支持,任何形式的平滑都不可避免地引入相位滞后。
既然如此,一个自然的思路是:在 VLA 推理时,模型其实已经隐含包含了“未来轨迹”信息,那么我们是否可以在发送给机械臂的轨迹上进行适当“预放大”,以抵消系统平滑造成的时延影响?
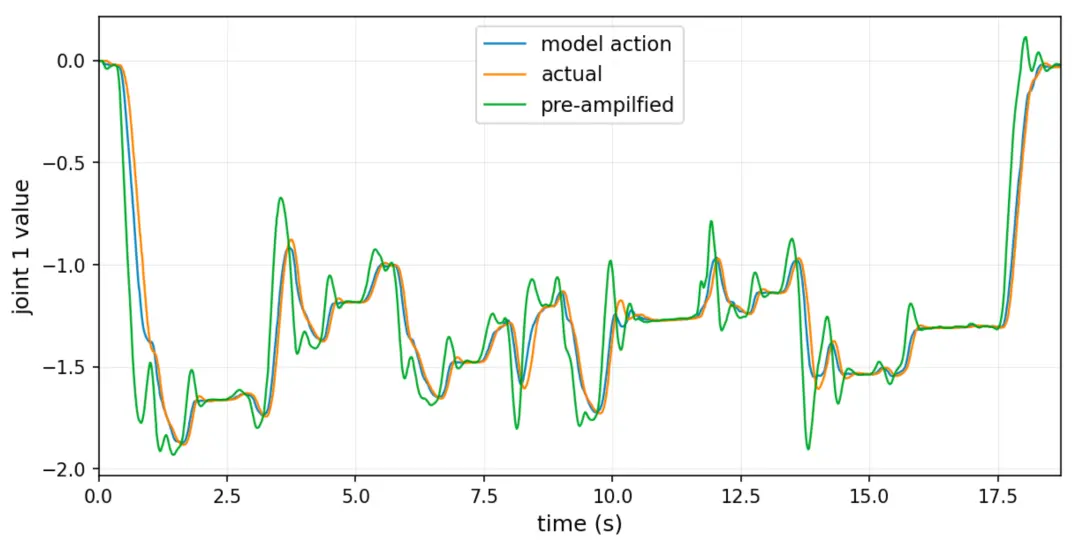
实验结果非常直观。如上图所示,当输入轨迹变成绿色所示那种经过适度“夸张”的形式后,机械臂的实际执行轨迹(橙色)就能更好地贴合模型原始输出(蓝色)。
但这一方案也带来了新的问题。带有明显“过冲”特征的控制信号,会显著增加机械臂抖动风险;而一旦机械臂抖动,相机随之抖动,视觉输入进一步恶化,再反馈到模型端后,系统很容易进入不稳定状态。
为此,我们在模型输出之后引入了额外的速度规划与位置规划,通过优化方法将高加速度段的变化分散到其他时段中,使最终下发给机械臂的轨迹既具备补偿效果,又不会引发过强抖动。
完成这些处理之后,对于大多数任务,系统已经可以直接 2x 速度下取得较为理想的效果。
挑战极限:上机器学习!
不过,我们对 2x 的状态仍然不完全满意。我一直在问一个问题:还能不能更快?
进一步分析动作序列后可以发现,不同阶段对速度的要求并不一致。比如在精细接触阶段,系统通常需要更慢、更稳;而在空中转移阶段,则完全可以更快。
于是,一个自然的方向就是加 RL:让系统自动学习“在什么时刻应该以什么速度执行”。
这类思路此前已有论文提出,代表性工作如 Speed Tuning。不过,任何涉及真实世界机器人 RL 的工作,落地起来都非常复杂。
这时,团队里一位实习生提出了一个非常有效的思路:既然采集过程中本来就需要有人在旁监控,不如直接让他加RL。于是,我们形成了目前最稳定、也最 work 的一种“油门式采集”方法:
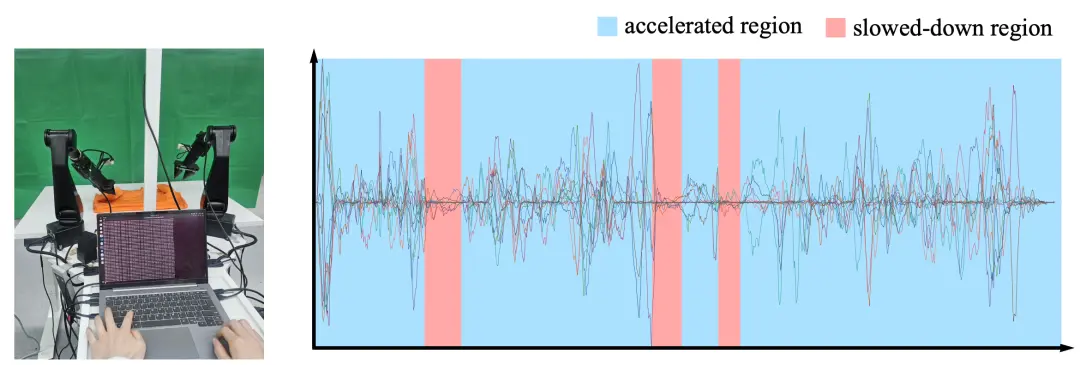
具体做法是:先让现有模型自主执行推理,人类站在旁边观察;当判断当前阶段可以更快时,就按下加速键;当感觉应当减速时,就按下减速键。这个过程很像在驾驶过程中踩油门和刹车,只不过调节对象变成了执行速度。
采集到这样的数据后,再用于训练新的模型,并持续迭代,我们便得到了一系列速度逐步提升的模型。
不得不说,人类确实是非常高效的真实世界自主 agent。我们发现,这种 DAgger-style 的迭代方式非常靠谱,几乎适用于各种任务,并且不太会引入复杂的系统不稳定问题。
也正因如此,机器人的执行速度得以进一步向前推进。
与人类速度的比较,以及进一步的边界
如果这是一个童话故事,那么结尾大概会是:“最终我们让机器人达到了媲美人类的速度,项目圆满完成。”但现实通常不会如此简单。
确实,经过上述优化之后,机器人在我们测试过的任务上的执行速度已经有了非常明显的提升。甚至在旁观其叠衣服时,已经能清晰听见关节电机高速运转的声音。我们还专门让人类以一种“不快不慢、但合理”的节奏,按照“机器人完成任务的方式”来执行同样任务,结果显示:在部分任务上,机器人确实已经接近“人手速度”。
但问题在于,人类从来不是以“机器人式”的方式完成任务。
人类双手在结构、力量分布、材料特性和控制自由度上,依然展现出极强的生物学优势。很多动作,人类可以以高度灵活、近乎一步到位的方式自然完成,而这些能力,目前的机器人硬件体系仍无法真正复制。
我们当然可以在六轴机械臂体系下持续探索其极限,但是离人的性能,还是差着很远。
另一方面,当我们把执行速度不断推高后,在各种延时的debuff下,VLA 模型本身其实也逐渐被推到了一个并不理想的工作区间:它需要在很高的提前量下以很准的要求输出未来位置。
所以在执行速度的这条路上,如果要继续走,必然还是要和硬件以及模型都再大战一番,才能再继续突破了。
这些问题,就留待未来继续解决。
不过,我们仍然希望通过这次工作的记录与开源,让更多人在构建机器人 demo 时,能够真正重视执行速度这一问题,而不是让行业外的人继续形成“用了 VLA 之后机器人只能慢吞吞动作”的刻板印象。
👇 点击下方卡片,一键预约直播!带你解锁VLA提速新技能。
